| Page de Titre Table détaillée |
|
I.S.I. Gramme |
| Page de Titre Table détaillée |
|
I.S.I. Gramme |
Faces cachées Le rendu (shading)
Tout programme graphique qui manipule des données en 3 dimensions, comme tous les programmes de CAO, doit afficher à l'écran la représentation bidimensionnelle de sa base de données. Ceci implique l'emploi de divers algorithmes de visualisation de polygones. Les premiers, car les plus fondamentaux, sont ceux qui déterminent si un polygone est ou non visible. Ensuite, il reste à afficher ce polygone avec divers rendus : c'est le 'Rendering' ou 'Shading'.
Deux grandes catégories de méthodes d'élimination des faces cachées existent pour construire des images 2D de solides convexes, concaves ou multiples. Il s'agit des méthodes dans l'espace-objet et des méthodes dans l'espace-image.
Les méthodes dans l'espace-objet utilisent les informations X, Y et Z de l'environnement 3D en 'World Coordinates' pour déterminer si une surface en cache une autre ou si elle est cachée par une autre. Typiquement, on utilise pour cela les formules de manipulation décrites au chapitre précédent.
Les méthodes dans l'espace-image utilisent les informations X et Y dérivées de l'image 2D en 'Device Coordinates' obtenue après application des formules de projection 3D -> 2D. On relève dix méthodes de base pour effectuer correctement l'élimination des faces cachées. Le choix de l'une ou de l'autre dépend de la complexité du modèle à visualiser, de la qualité de rendu désirée et des performances de l'interface graphique dont on dispose.
En effet, certaines de ces méthodes sont très voraces en mémoire ou en temps de calcul. La solution optimale est le plus souvent une combinaison de diverses méthodes parmi celles que nous allons décrire. En effet s'il existe des méthodes qui sont valables dans tous les cas, ce sont en général les plus lourdes à mettre en oeuvre. Un test de la complexité du cas permet souvent de choisir la méthode de complexité 'juste nécessaire' à résoudre le problème.

On l'appelle aussi la méthode du tri préalable. C'est une méthode espace-objet'. Elle consiste conserver triées les entités géométriques par ordre de leur distance à la caméra. En affichant à l'écran les objets les plus lointains pour commencer, on les cache successivement en dessinant 'par dessus' les objets les plus proches. Pour autant que le point de vue soit connu d'avance ou même fixe, il suffit d'ordonner physiquement en mémoire les entités à afficher. La routine d'affichage n'a alors plus aucun effort à consentir pour que l'image soit correcte. Evidemment, tout changement de point de vue oblige à modifier l'ordre d'affichage. Cette méthode convient donc bien pour des modèles fixes vus d'un point de vue fixe.
C'est aussi une méthode espace-objet'. Ici la séquence d'affichage des entités n'est plus fixe, mais mémorisée dans une liste calculée, qui dépend de la position du point de vue. Si plusieurs points de vue doivent être utilisés, on peut mémoriser une série de listes et choisir l'une ou l'autre en fonction de la valeur de l'angle de vue. Ainsi, dans les simulateurs de vol ('Flight Sim'), les immeubles et les avions possèdent tous six listes des faces à afficher suivant que la vue soit faite de haut, bas, gauche, droite, dessus ou dessous. De même, il existe des listes d'immeubles à afficher pour des points de vue dans telle ou telle direction, etc...
Voici encore une méthode espace-objet'. Nous en avons parlé au chapitre précédent en cherchant à déterminer l'équation d'un plan. Une fois celle-ci trouvée, il est très simple de savoir si un point (la caméra) est du côté visible ou du côté invisible d'une facette polygonale. Cette méthode est infaillible pour un solide géométrique convexe et unique, comme un polyèdre régulier.
Dès que plusieurs polyèdres existent dans la scène à afficher, cette méthode seule ne suffit plus, sauf dans le cas particulier où aucune face d'un polyèdre ne risque de cacher l'autre polyèdre. Il faut donc conjuguer cette méthode avec une autre, comme celle du tri radial ci-dessus. L'équation du plan est d'abord utilisée pour ne conserver que les faces orientées vers la caméra, puis la méthode de tri radial affiche ces faces dans le bon ordre, les plus lointaines d'abord.
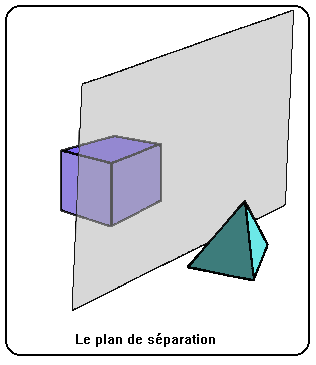
Voici une autre méthode 'espace-objet'. Elle est basée sur l'équation du plan, mais trouve son intérêt dans les scènes à objets multiples. Si nous plaçons un plan imaginaire entre deux objets de la même scène, on peut utiliser l'équation du plan pour savoir de quel côté est la caméra, et donc déterminer quel objet est du bon côté du plan et doit donc être affiché en dernier lieu.
Il suffit d'avoir les équations d'un certain nombre de plans séparant les divers objets à afficher pour pouvoir les trier. En effet, la méthode du tri radial devient impraticable dès que le point de vue peut varier arbitrairement suivant les trois axes car le nombre de listes triées à mémoriser risque de grossir très vite.
Cette méthode est celle utilisée dans le célèbre jeu d’action 3D DOOM et nombre de ces successeurs.
Voici encore une méthode espace-objet'. Elle est utile dans les scènes à objets multiples se recouvrant partiellement. Chaque objet peut être projeté sur un plan perpendiculaire à l'axe de la caméra. Après cette projection, les divers plans sont eux-mêmes affichés en séquence après avoir été trié par ordre de Z croissants. En effet, les plans dont la coordonnée Z, c'est-à-dire la distance à la caméra est la plus grande ont les coordonnées les plus négatives. Cette méthode est d'autant plus facile à appliquer que les objets à afficher sont plans ou en tous cas, faciles à projeter sur des plans transversaux.
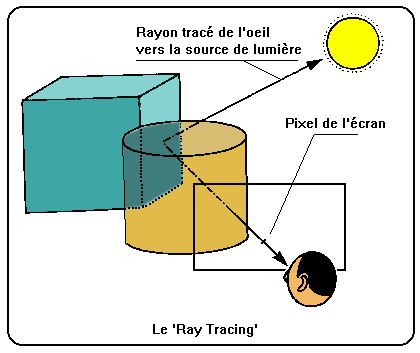
Voici encore une méthode 'espace-objet'. Cette méthode a conquis sa notoriété non pas à cause de ses perfor–mances en vu/caché, mais à cause de son excellent rendu des om–bra–ges et des transpa–rences. Mais, malgré tout, elle reste la meilleure des méthodes de vu/caché qui existe. Son seul inconvénient est cependant de taille : Le ray tracing est épouvantablement vora–ce en temps de calcul et en espace mémoire.
Par chaque pixel de l'écran, on imagine que passe un rayon lumineux qui se dirige vers la caméra. On remonte le cours de ce rayon dans ces réflexions et réfractions diverses, jusqu'à atteindre la source de lumière qui l'a créé. On connaît alors la couleur de ce rayon qui dépend, comme dans la réalité, de tous les matériaux et de toutes les lampes qui ont contribué à le créer.
Voici encore une méthode espace-objet'. Cette méthode est utilisée dans les programmes CSG (les modeleurs volumiques) qui décomposent le volume de l'objet modélisé en volumes élémentaires. On imagine que n'importe quel volume complexe est en fait constitué d'un très grand nombre de cubes élémentaires. Ces modèles permettent un calcul aisé des centres de gravité et d'inertie. Pour afficher ce type d'objet correctement, il suffit d'afficher les sous-éléments (les cubes élémentaires) les plus lointains en premier lieu (avec l'algorithme du peintre ou un des autres).
Voici notre première méthode espace-image. Une table de données est tenue à jour. Elle contient la coordonnée Z de chaque pixel affiché à l'écran. Pour cela, lors de la transformation en coordonnées 'DC', on transfère la valeur Z de la troisième coordonnée à l'emplacement correspondant de la table. Cette table est appelée 'Z-Buffer'. Dans de nombreuses stations de travail (notamment les machines Silicon Graphics), le Z-Buffer existe dans la partie câblée de la carte d'affichage écran. Il n'est pas indispensable que cette fonction soit câblée car elle peut aussi être réalisée de façon logicielle. Si la table possède une précision de 16 bits par valeur Z, il est nécessaire de consacrer au Z-Buffer une taille de 2 octets par pixel (soit 614.400 octets pour un écran de 640x400 pixels, ou 128.000 octets pour un écran de 320x200 pixels).
Si à l'emplacement du pixel à afficher, une valeur Z existe déjà, on compare cette valeur à la valeur Z du nouveau pixel. Si la valeur Z du nouveau pixel que l'on ajoute est supérieure à celle du pixel déjà affiché à cette même place, c'est qu'il est plus proche de l'observateur que ce dernier, et il peut donc prendre sa place. On affiche donc le nouveau pixel à l'écran et on met à jour le Z-Buffer. Dans le cas contraire, le pixel déjà présent est conservé et le Z-Buffer n'est pas modifié.
Cette méthode est correcte dans tous les cas, quelle que soit la complexité de la scène, le nombre et les positions relatives des objets, etc. Malheureusement, elle coûte cher en temps de calcul et en espace-mémoire, sauf dans les cas où elle est implantée dans le hardware de la machine. Les puissances de calcul nécessaire sont heureusement de plus en plus accessibles.
Note : il convient de bien choisir à quelle distance en z correspondent les minima et maxima des valeurs stockées dans le Z-Buffer pour garder une bonne précision dans les intersections d'objets. Si de nombreux objets presque parallèles au plan de l'écran s'intersectent, une précision importante est demandée. Il faut alors réduire la profondeur de la zone utile du Z-Buffer ou lui consacrer un nombre élevé de bits par pixel.
On notera que depuis 1997, la fonction Z-Buffer est câblée dans toutes les cartes accélératrices 3D dignes de ce nom (3DFx, ATI Rage, etc…)
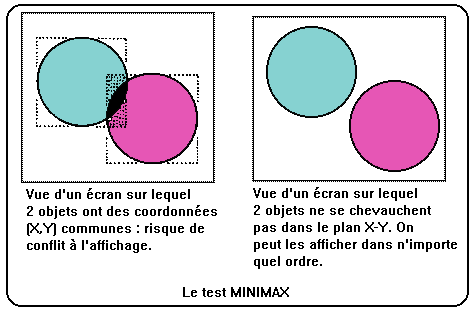
C'est aussi une méthode espace-image. Comme on le voit dans la figure, les valeurs mini et maxi des coor–données X et Y de deux plans sont analysées pour voir s’il y a des risques de recouvrement d'un objet par un autre. Si le maximum en X d'un objet est plus petit que le minimum en X d'un autre objet, ils ne se cacheront pas l'un l'autre. On peut donc les dessiner dans n'importe quel ordre. Si par contre, il existe un risque de conflit, on recourt à une des méthodes espace-objet déjà exposée ci-avant. Ce sera usuellement la méthode Z-Buffer ou l'algorithme du peintre. Le Minimax permet, par un simple jeu de comparaisons, d'éliminer un part qui peut être non négligeable du temps de calcul demandé par ces algorithmes.
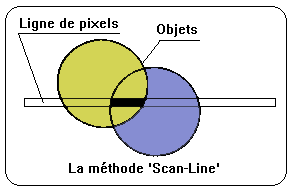
Cette dernière méthode est aussi une méthode espace-image. Elle est directement dérivée de la méthode Z-Buffer. Dans ce cas, on ne mémorise pas une table de Z pour tous les pixels de l'écran, mais seulement pour tous les pixels d'une ligne horizontale de l'écran. L'image est alors calculée ligne par ligne. Pour chaque polygone à afficher, on cherche d'abord s'il coupe l'horizontale correspondant à la ligne-écran en cours. Si oui, on agit comme dans le cas du Z-Buffer. Cette stratégie est appliquée pour chaque ligne de l'écran à tous les polygones de la scène à afficher. Cette méthode est plus pénalisante en temps de calcul que la méthode Z-Buffer, mais elle est moins vorace en espace-mémoire.
Le choix d'une méthode se fera sur base de la complexité des scènes à afficher, du fait que la caméra est appelée ou non à changer fréquemment de place, et de la puissance de l'ordinateur utilisé. si ce dernier critère n'est pas contraignant, la solution la moins contraignante pour le programmeur est la méthode Z-Buffer. Mais souvent le choix est restreint à une ou quelques méthodes qui sont utilisées par la bibliothèque de sous-programmes graphique que l'on utilise. Mais presque toujours, on utilise en premier lieu l'équation du plan pour déterminer si la face du polygone concerné est orientée vers la caméra ou non.
Les diverses méthodes de rendu existantes sont très différentes aussi bien en efficacité qu'en besoin de puissance informatique. La puissance des processeurs n'est pas infinie et on se contentera donc d'utiliser l'algorithme juste suffisant pour le degré de réalisme que l'on désire obtenir.
Tous ces algorithmes déterminent la couleur d'un pixel affiché à l'écran. On utilise pour cela diverses informations comme l'orientation et la couleur du polygone que l'on affiche, la couleur, l'orientation et la position des lampes éclairant la scène, la position d'un objet par rapport à l'autre, le matériau dont est constitué l'objet, son état de surface, etc.. Les méthodes utilisées dépendent aussi des performances de l'écran de visualisation utilisé.
Les méthodes ne sont pas les mêmes si l'écran dispose de 16 ou 256 couleurs ou bien d'une palette complète de 16 millions de nuances. Dans tout l'exposé ci-dessous, on considèrera que l'on dispose du meilleur écran. Dans le cas des écrans moins performants, on adopte diverses méthodes de conversion de 'vraie' couleur dans les couleurs disponibles (comme les méthodes de 'half-toning', par exemple).

La première et la plus simple méthode consiste tout simplement à donner aux pixels de l'écran correspondant à un polygone la couleur de celui-ci. Comme inconvénient, on constate évidemment que le résultat ne rend aucun effet de volume. Il n'y a aucun ombrage, aucune séparation permettant de distinguer un polygone orienté vers la gauche d'un polygone orienté vers la droite, etc. Du côté des avantages, on constate aussi qu'il n'y a aucun calcul à faire concernant la couleur du pixel à afficher.
En No-Shade, si un objet est de couleur uniforme, on distingue à l'écran une zone de couleur uniforme et seul le contour externe de l'objet est reconnaissable.
Le premier vrai algorithme de rendu est aussi un des moins voraces en temps de calcul. Il fait intervenir un paramètre extérieur à l'objet à visualiser : la direction de la source de lumière.
Supposons que la scène est éclairée par une source de lumière blanche située à l'infini. Elle est caractérisée par un vecteur unitaire qui donne l'orientation des rayons lumineux parallèles qui en émanent. Pour chaque facette polygonale à afficher, on va calculer une couleur qui dépendra de la couleur de l'objet et de l'angle d'incidence entre la normale au plan de la facette et le vecteur 'éclairement'. On applique la loi de Lambert ou 'loi du cosinus'.
On fait ici diverses hypothèses, pas toujours très conformes à la réalité : la source de lumière est à l'infini, la caméra est à l'infini et la facette est réellement la surface de l'objet et non son approximation. Les deux premières hypothèses permettent de supposer les divers vecteurs intervenant dans le calcul comme parallèles. La dernière (et la moins correcte) implique que l'on ait des variations brusques d'éclairement aux arêtes entre deux facettes voisines.
![]()
La loi de Lambert précise qu'une surface apparaît d'autant plus brillante que son vecteur normal est orienté en direction de la source de lumière. Plus l'angle entre cette normale et le rayon lumineux est grand, plus la surface paraît sombre. La surface ne réfléchit plus aucune lumière si elle est perpendiculaire au rayon lumineux ou, a fortiori, si elle est orientée 'à l'envers'.
Usuellement, on fait intervenir une lumière ambiante omnidirectionnelle. Par exemple, si la lumière ambiante intervient pour 10% de l'éclairement, la couleur d'une face sera donnée par :
![]()
où A est l'angle entre le vecteur 'éclairage' et la normale à la surface.
Pour un objet quelconque, il y a trois façons de réfléchir la lumière. On les appelle réflectances diffuse, ambiante et spéculaire. La lumière ambiante est la lumière diffuse, comme celle d'un jour nuageux. On n'observe pas d'ombres, car la source de lumière est également répartie dans toutes les directions. Un exemple type d'éclairage diffus est l'éclairage naturel dans une pièce dont les fenêtres donnent sur le nord.
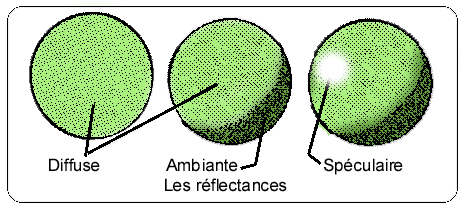
Un modèle d'objet solide soumis à un éclairage diffus uniquement pos–sède une réflec–tance diffuse, et la loi de Lambert n'est pas applica–ble.
La réflectance ambiante est pro–duite par une lumière distribuée éclairant un objet. La lumière distribuée provient d'une source lumineuse large, puissante et relativement proche de l'objet éclairé. Les ombres existent et sont bien visibles. Il s'agit, par exemple de la lumière produite par des rampes de tubes fluorescents dans une pièce ou de toute autre source de lumière non ponctuelle.
La réflectance spéculaire est produite par une source de lumière ponctuelle éclairant un objet relativement lisse et brillant. On y voit un point de lumière vive qui est l'image (comme dans un miroir) de la source de lumière. Ce reflet de la source possède la même couleur que la source de lumière elle-même, tandis que dans le cas des réflectances diffuse et ambiante, les réflexions (highlights en anglais) ont la teinte de l'objet.
On tient compte de la rugosité de l'objet pour créer des 'spots' ou highlights plus ou moins brillants. Pour cela, on fait intervenir dans le calcul de la luminosité un terme en cos(A) affecté d'un exposant plus ou moins important (de 1 à 200 environ). L'importance de ce terme est établie par un facteur k (proportion de l'éclairage spéculaire par rapport à l'éclairage diffus) :
![]()
Il est à remarquer que cette loi est une loi empirique. Elle ne découle pas directement d'une loi de l'optique utilisée à des fins de simulation, mais du fait que l'effet obtenu est suffisamment satisfaisant.
La perception que nous avons d'un objet dépend fortement de son état de surface. Celle-ci peut être transparente ou opaque, matte ou lisse, etc. Une surface transparente permet à une grande part de la lumière de pénétrer dans l'objet. Elle réfléchit donc moins de lumière. C'est la cas du verre, du plexiglas, de l'eau et des films plastiques.
Les surfaces translucides ne laissent passer que certains rayons lumineux et réfléchissent les autres. C'est la cas des plastiques couvrant les clignoteurs des voitures, par exemple.
Les surfaces opaques réfléchissent une partie de la lumière incidente et en absorbent une partie. La planéité de la surface influence fortement le taux d'absorption de lumière. Une brique ordinaire absorbe une portion notable de la lumière reçue, elle est donc assez sombre.
Une surface très lisse et opaque comme celle d'une bille d'acier ou d'un miroir présentera surtout des réflexions spéculaires. De nombreux génériques de télévision usent et abusent des effets spéculaires sur des logos d'aspect métallique, car ils mettent en valeur les mouvements de caméra.
La rugosité peut être chiffrée par un nombre compris entre 0 et 1, qui sera utilisé comme paramètre pour choisir l'algorithme d'éclairement approprié. Un objet 100% rugueux réfléchira la lumière dans toutes les directions, tandis qu'un objet lisse à 100% obéira strictement à la loi de Lambert.
Une surface présente un aspect 'miroir' si elle possède uniquement la couleur de la source lumineuses qui l'éclaire (voir réflectance diffuse).
Une surface a un aspect métallique si elle réfléchit la couleur de la source lumineuse près de la perpendiculaire, et sa couleur propre quand on s'en éloigne. La fonction ne doit toutefois pas être continue, pour simuler au mieux les irrégularités microscopiques des matériaux métalliques (grains allongés de l'acier, grains arrondis du zinc ou du plomb, aspect 'brossé' de l'aluminium).
La méthode Gouraud permet d'obtenir le rendu d'un polyèdre avec un aspect 'lissé', sans qu'il n'y ait de variation soudaine de couleur ou de luminosité au passage entre deux facettes contiguës. Pour tout l'objet, on calcule la direction de la normale à la surface en chacun des sommets. Il suffit de prendre la somme vectorielle des normales aux facettes contiguës et de la normer.
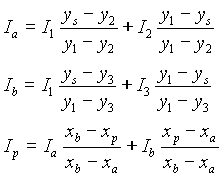
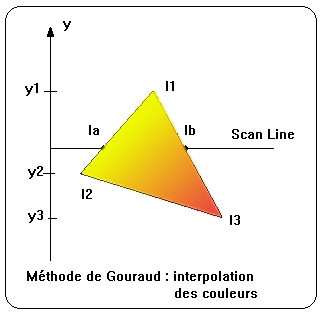
Lors de l'affichage des pixels corres–pondant à une face, on détermine la couleur de la facette en chacun de ses sommets, et les pixels de toute la facette en sont déduits par une simple inter–polation linéaire. On peut facilement vérifier qu'il n'y a pas de discontinuité dans les teintes entre deux facettes adjacentes : dans les deux facettes qui partagent une arête commune, les couleurs aux extrémités sont identiques car elles dépendent uniquement des normales précalculées en ces deux points. Les pixels intermédiaires de l'arête sont bien identiques sur les deux facettes, car obtenus de la même façon par une interpolation linéaire entre les couleurs des deux sommets.
Les programmes professionnels sur les stations de travail (Silicon Graphics, Hewlett-Packard, etc..) bénéficient de plus en plus souvent d'une implémentation hardware de cet algorithme. Ils effectuent généralement cet ensemble de calcul pour un certain nombre de sources de lumières qui peuvent être colorées (composantes R, G et B différentes), et situées à des distances finies.
On remarquera que le calcul est grandement facilité quand la source de lumière est unique et située à l'infini, car les rayons lumineux sont alors parallèles, et un des deux vecteurs entre lesquels ont mesure l'angle pour la loi de Lambert est donc toujours connu. Au contraire, dès que la source de lumière est proche, la distribution de ses rayons lumineux est sphérique et la direction doit être recalculée à chaque coup. de plus l'intensité du rayonnement décroît en raison du carré de la distance, et une simulation réaliste d'éclairage doit en tenir compte.
L'algorithme de Phong est bâti sur la même base, mais au lieu d'interpoler les valeurs de couleurs obtenues, on interpole les directions des normales pour obtenir une normale à l'objet en chacun des pixels que l'on veut afficher. Le calcul est donc plus correct, mais nécessite environ cinq à dix fois plus de puissance de calcul. Le résultat est cependant nettement meilleur, notamment pour les 'highlights' provoqués par des sources de lumière proche. Dans ces cas, la valeur de l'angle d'incidence de la lumière sur l'objet n'est pas réalistement représentée par des interpolations linéaires car les angles entre lumière et surface peuvent varier très fortement.
Phong : méthode à utiliser si les sources lumineuses sont proches des objets |
Le problème du shading n'implique pas que le calcul de divers angles entre surface et rayons lumineux. Il faut aussi que les rayons en question atteignent la surface. Ce n'est pas toujours le cas, car un objet peut être partiellement ou totalement dans l'ombre d'un autre objet. Pour savoir si une source de lumière ponctuelle éclaire ou non un point d'une surface, il suffit d'appliquer un algorithme de 'vu-caché' comme on les a détaillés ci-dessus, en remplaçant la caméra par une source de lumière.
On comprend aisément que les temps de calcul augmentent de façon très importante dès que l'on prend en compte ces phénomènes. Diverses méthodes permettent de réduire le nombre de calculs à effectuer. Ainsi, les ombres ne changent pas de place si la caméra se déplace, mais pas les sources de lumière. Comme ce cas est fréquent, on en profite pour ne calculer qu'une seule fois les zones d'ombre pour tous les points de vue successifs.
Les zones d'ombres sont calculées comme des 'seconds polygones' qui recouvrent les facettes de l'objet. Les facettes sont utilisées pour le calcule de 'vu-caché' et les 'seconds polygones' pour déterminer si un pixel est illuminé de façon ambiante (zone d'ombre) ou ambiante et spéculaire (zone éclairée).
La technique de Ray Tracing ou lancer de rayon étudie le trajet du rayon lumineux aboutissant à la caméra et passant par un pixel de l'écran. En respectant les lois de l'optique, on réalise ainsi des images fort réalistes d'objets divers, même transparent ou translucides. Il suffit de tenir compte lors des réflexions et réfractions des rayons des paramètres réels de transmission, comme transparences à diverses couleurs, indice de réfraction, taux d'opacité. Les algorithmes de Ray Tracing impliquent une quantité de calculs absolument phénoménale. Les puissances de calcul nécessaires sont donc très grandes et donc le coût de cette technique est très élevé.
En effet, lors de chaque réflexion ou réfraction, seule une partie du rayon est dévié et il faut donc suivre les deux branches du rayon en leur accordant un 'poids' à chacun. Ce processus se poursuit jusqu'à ce que les rayons aient tous atteint une source de lumière ou le fond de la scène, ou que leur poids respectif soi jugé négligeable. Les rayons qui passent par une source de lumière prendront les caractéristiques de cette source. Les rayons provenant du fond de la scène seront soit noirs (pas de lumière), soit prendront le couleur du 'ciel', c'est-à-dire une couleur de fond fixée à priori.
La plupart des algorithmes de ce genre limitent le nombre de réflexions prises en compte à deux ou trois. Malgré ce genre de limitations, le calcul d'une image peut durer entre plusieurs heures et plusieurs jours pour des scènes complexes (sur des mini-ordinateurs de taille moyenne).
Pourquoi une telle durée? Tout simplement, parce qu'à chaque fois que l'on trace un rayon, il faut calculer son intersection éventuelle avec toutes les facettes polygonales de la scène, et ceci arrive de nombreuses fois pour chaque pixel de l'écran. Par exemple, on peut estimer que pour une image de 480x640 pixels (un écran VGA) comportant 200.000 polygones et 5 sources de lumière, le nombre de calculs à effectuer sera de l'ordre de 480x640x200.000x5x20, soit 6.000 milliards! (pour un PC de 500 Mflop de puissance de calcul, il faut plus de 3 heures) En pratique, des algorithmes intelligents du genre Minimax réduisent ce nombre aux environs de dix milliards (c'est quand même beaucoup!).
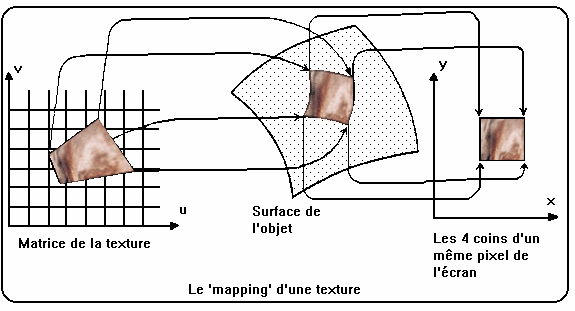
Tout le monde est familiarisé par la télévision avec des vues d'images vidéo qui semblent fixées aux faces d'un cube en rotation. Ce type d'effet est appelé 'texturage de surface'. Cette technique est très utilisée pour 'habiller' les modèles réalisés par les programmes modeleurs. Ainsi une texture 'marbre' ou 'brique' appliquée à un mur de maison donne des effets bien plus réalistes qu'une couleur rouge ou grise uniforme.
Les textures colorées sont en fait des images bitmap souvent (mais pas obligatoirement) réalisée avec une caméra filmant un objet réel. On se représente une surface infinie
composée d'un grand nombre d'images identiques (des briques, par exemple). Cette surface est ensuite déroulée sur la surface de l'objet modélisé. Les facettes ont ainsi un grand nombre de points de couleurs variées. La couleur réelle est calculée à partir de l'image de texture et utilisée lors du processus de vu-caché et de shading. Les surfaces ont ainsi un aspect beaucoup plus réaliste.
Les textures à 3 dimensions sont des algorithmes de calcul qui donnent à chaque point de l'espace une couleur qui ne dépend que de sa position. Quand on dessine une surface avec ce type de texture, les coordonnées X,Y et Z de chaque point de la surface sont fournies à l'algorithme de texture 3D, qui détermine la couleur correspondante. On réalise en textures 3D des surfaces d'aspect bois, marbre, pierre, fibres, etc. sans avoir de problèmes dans le cas des surfaces non développables.
Elles conviennent mieux pour les objets de forme complexe, mais ne permettent pas d'atteindre la même précision ni surtout la même variété de détails que la méthode des textures 2D. De par leur nature algorithmique, les textures 3D sont aussi appelées 'textures procédurales'.
Seules les textures bitmap peuvent être mémorisées dans les cartes accélératrices 3D. Quand elles le sont, le taille totale des textures utilisables dépend de la taille mémoire de la carte graphique en question (suivant les cartes, cela peut aller de 4 Mb à 64Mb et plus…)
Le bump-mapping est un texturage de surface 2D ou 3D, comme on l'a décrit ci-dessus, sauf que cette texture ne sert pas à définir la couleur de la surface, mais plutôt à y inscrire des détails en relief. La méthode de Blinn consiste à perturber la direction de la normale à la surface, ce qui affecte la brillance de la surface, comme si elle était déformée. Bien que les bords extérieurs de la surface ne soient pas déplacés, l'effet obtenu est très satisfaisant.
Les méthodes fractales développées par Fournier et Carpenter sont depuis les années 90 utilisées pour donner à une surface un aspect chaotique. Elles sont utilisées pour donner des aspects 'forêt', 'flocons de neige', ou 'cailloutis' ou même 'fourrure'. On obtient par exemple un décor de montagnes en subdivisant un quadrilatère en parties de plus en plus petites auxquelles on affecte des altitudes au hasard (autour d'une valeur moyenne). Cette procédure est reproduite récursivement jusqu'à obtenir le degré de complexité recherché. Elle utilise une puissance de calcul fort importante.

L'aspect en escalier des lignes obliques sur un écran peut être atténué de façon à rendre moins visible cet artefact qui n'est dû qu'à la technique de balayage des écrans. La méthode la plus simple d'anti-alias (anticrénelage en français) est de calculer chaque image avec une résolution double (ou triple) dans chaque direction X et Y, puis de calculer chaque pixel définitif en prenant la moyenne des quatre pixels qui lui correspondent.
Par exemple, on calcule l'image en résolution 1280x960 et on l'affiche ensuite en résolution 640x480. On constate alors qu'une ligne oblique noire sur fond blanc est affichée avec des pixels qui présentent quatre niveaux de gris, résultat du calcul de moyenne effectué sur quatre pixels à chaque fois. L'effet est bien plus satisfaisant pour l'œil, mais le temps de calcul est multiplié par quatre.
Cette méthode étant applicable très 'localement' (ne dépendant que des quelques pixels avoisinants) peut être approchée de manière peu coûteuse par un dispositif électronique dans la carte d'affichage elle-même. Il existe aussi seur les cartes VGA un mode dit '32.000 couleurs' ou ‘milliers de couleurs’. Il s'agit en fait de cartes graphiques travaillant en vraies couleurs codées sur 15 ou 16 bits (5 par composante, 6 pour le vert dans la cas du 16 bits).
Note : Les cartes récentes ont toutes un mode vraies couleurs en 24 ou 32 bits (8 bits par composante). Le mode 32 bits est un mode 24 bits avec 8 bits inutilisés pour optimiser les transferts mémoire sur les bus qui possèdent 32, 64 ou 128 bits. Les cartes graphiques haut de gamme en 1999 possèdent 16 ou 32 Mb de mémoire permettant un mode ‘true color’ 32 bits en des résolutions atteignant 1600x1200, ce qui nécessite 4x1600x1200 = 7.7 Mb), le reste de la mémoire servant au Z-buffer et aux textures.
Les effets de reflets en Ray-Tracing sont très appréciés mais souvent trop onéreux. Quelques astucieux ont découvert une solution à moindre coût. On imagine que la scène se déroule au centre d'une sphère qui est tapissée avec une image du contenu de la sphère. Souvent, cette image est une portion d'une scène réelle comme un paysage, ou encore un décor avec terre, mer et ciel.
Sur chaque objet de la scène qui offre une réflectance spéculaire, on utilise comme source de lumière un point de la sphère de reflection map. Les objets reflètent ainsi tous l'aspect d'un même décor cohérent. L'effet est moins conforme à la réalité qu'avec le Ray-Tracing, mais le différence de coût est telle que très souvent on lui préfère le 'truc' de la reflection map.
Quand un écran ou une imprimante ne possède pas assez de niveaux de gris ou de couleurs différentes, on peut réduire artificiellement la résolution de l'écran pour améliorer le rendu des couleurs. Pour cela, on divise l'écran en zones de quelques pixels de côté (de 2 à 8) et on utilise une proportion variable de deux teintes dans chacune des zones pour donner l'illusion d'un nombre de couleurs supérieur. On approche ainsi la méthode de reproduction par points des photos de journal, qui sont imprimées avec des points noirs de taille variable.
Pour un ordinateur, les couleurs sont définies par trois valeurs numériques R, G et B (rouge, vert et bleu). En réalité, l'œil est sensible à un spectre électromagnétique de 350 à 750 nm de longueur d'onde.
Bleu = 400 nm
Vert = 600 nm
Rouge = 750 nm
Une source de lumière quelconque est définie par un spectre précis dans cette gamme de valeurs. La description d'un tel spectre nécessite bien plus de trois valeurs numériques. Pourtant l'oeil, étant un capteur fort imparfait, peut être assimilé à un groupement de trois capteurs, un correspondant au centre du spectre (le vert) et les deux autres aux extrémités (le rouge et le bleu).
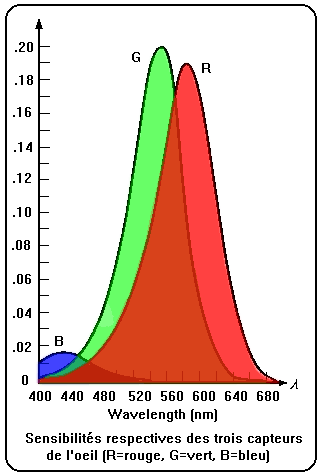
L'œil peut être assimilé à un capteur filtré dont la sensibilité maximale correspond au vert. Ainsi, un écran doit donner plus d'intensité à du rouge ou à du bleu qu'à du vert pour obtenir une luminosité apparente ou brillance (brightness) équivalente. En fait, les trois type de cellules de l'œil correspondent à des spectres plus ou moins étalés dont les centres sont le bleu (B), le vert (G) et le vert-jaune (R) dont le spectre couvre la partie basse des fréquences jusqu'au rouge. N'importe quelle couleur qui donne à ces trois types de capteurs le même niveau de stimulus (l'intégrale de la brillance dans le spectre des courbes ci-dessus) est indiscernable d'une autre qui offre le même 'tristimulus'.
Donc, le fait de n'utiliser que trois types de sources lumineuses sur un écran est suffisant pour correspondre à la réalité.
La luminosité 'noir et blanc', c'est-à-dire la valeur physiologique de brillance globale se déduit des valeurs R, G et B par la formule :
![]()
D'ailleurs, aux faibles valeurs de luminosité, l'œil n'est plus sensible à la couleur et ne perçoit plus que des écarts de luminosité (la nuit par exemple). L'œil est en effet sensible à une très large plage d'intensités lumineuses : sa réponse est logarithmique. Mais, dans les luminosités 'confortables' qui peuvent être générées par un écran vidéo ou cinéma, la perception des luminosités peut être considérée comme linéaire sans grande erreur.
Si on se contente de 8 bits pour stocker les intensités des trois stimuli R, G et B, on dispose déjà de 224 couleurs différentes, soit un peu plus de 16 millions. Ceci est appelé 'True Color' et suffit pour que l'œil ne perçoive plus de variations importantes entre 2 couleurs voisines.
Pour obtenir des images de qualité parfaite, comme pour le cinéma grand écran, on manipule les couleurs en 12 bits par composantes, car avec 8 bits, l'œil arrive encore à discerner des artefacts introduits dans l'image par le procédé digital. Ainsi, une échelle de gris (où R=G=B) ne contient que 256 valeurs différentes en 8 bits/composante, tandis qu'avec 12 bits, on passe à 4096 valeurs différentes.
Les ordinateurs qui ne disposent que de 1, 2 4, ou 8 bits pour stocker la totalité des couleurs emploient une table (la LUT) pour convertir les n valeurs disponibles en valeurs 'true color' (usuellement codées sur 24 bits). Ainsi, une carte PC VGA de base dispose de 256 couleurs (8 bits par pixel) parmi une palette de 256.000 environ (table à 6 bits par composante de couleur). Les valeurs mémorisées dans la mémoire écran ne sont donc plus des couleurs, mais des numéros de ligne de la table LUT. L'électronique de la carte écran convertit ces numéros en valeurs binaires de couleurs réelles qui sont ensuite transformées (par 3 convertisseurs numérique-analogique) en tensions de contrôle pour l'écran vidéo d'affichage.
N° de couleur |
R |
G |
B |
0 (Rouge) |
1.0 |
0.0 |
0.0 |
Malgré l'universalité de l'emploi des valeurs R, G, B par les systèmes électroniques d'affichage, les programmes d'imagerie manipulent parfois les couleurs sous d'autres formes, en général des triplets de valeurs, parfois des quadruplets (pour l'impression papier, on utilise le système CMYK ( Cyan, Magenta, Yellow, blacK).
La plus utilisée de ces méthodes alternatives est le système HLS où les couleurs sont définies par trois paramètres : Hue (la teinte), Luma (la luminance) et Saturation (la brillance). La teinte varie généralement de 0° à 360° le long d'un cercle. La luminance de 0 à 1 indique la luminosité générale de la teinte. La saturation permet de contrôler si on emploie la teinte pure ou mélangée à du blanc (0 = teinte pure, 1= blanc). Ce système peut avoir ses avantages, mais possède un gros inconvénient : il n'est pas univoque. Par exemple, n'importe quelle teinte saturée à 100% donne du blanc pur. Ce système est donc moins facile à gérer par programme.
![]() (fin du cours)
(fin du cours)
Cette page est copyright B.Michel, 2009